RU
Всем привет!
Хочу выразить согласие с некоторыми идеями, описанными в данной ветке. Сообщество растёт быстрыми темпами, и ситуации, описанные участниками конкурсов, будут повторяться раз за разом.
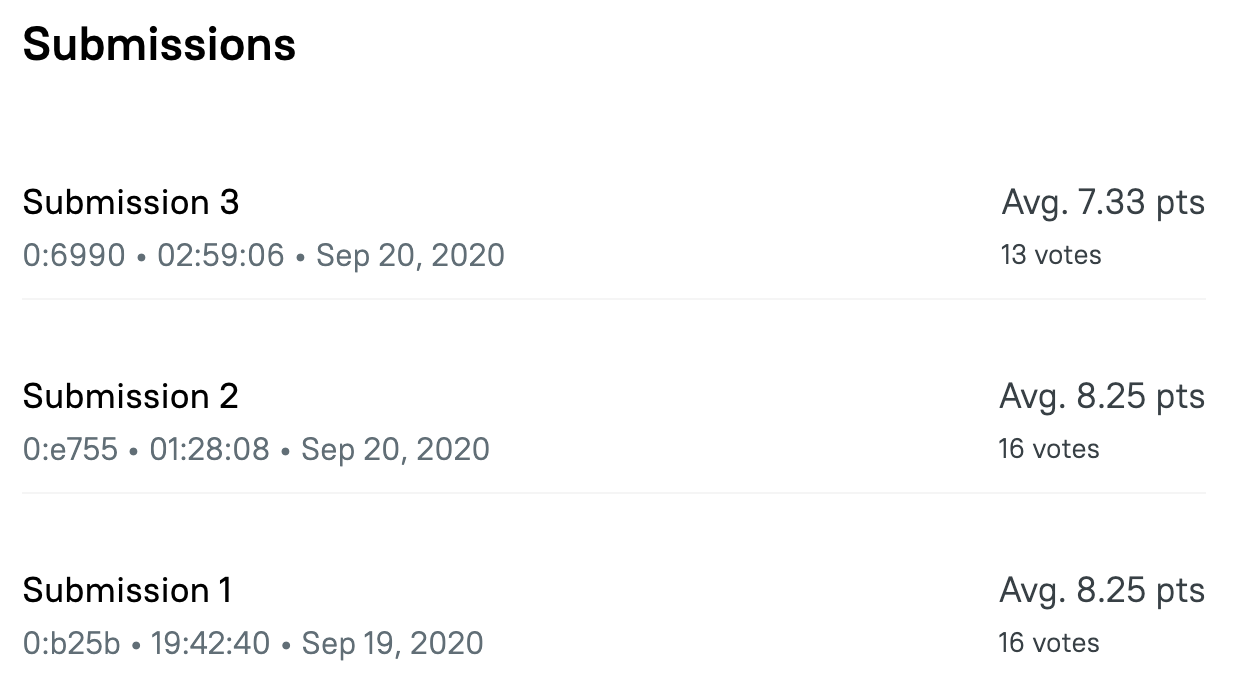
Наша команда не стала исключением. Мы так же участвовали в конкурсе Atomic Swaps (Contest: Atomic Swaps on Free TON [31 August 2020 - 20 September 2020]). Единственная и самая низкая оценка 7, полученная от жюри для нашей работы под номером 1 выглядела так:

Можно предположить, что член жюри снимал по 1 баллу за указанные им недостатки. Но суть в том, что ссылки на транзакции (второй снятый балл) есть и указаны под каждой видео-демонстрацией, о чем было сказано в submission.
Взимание комиссии (первый снятый балл) так же реализовано, о чем я подробно написал в ветке конкурса в этом посте. Читал ли член жюри эту ветку, где и другие участники конкурса давали ответ на данный вопрос – я не знаю.
Можно так же поспорить, является ли использование хорошо работающих частей open source проектов в других open source решениях после review кода и необходимых правок - не правильным, или же наоборот предпочтительным (в нашей практике заказчики предпочитали open source решение, при условии, что оно production-ready).
Но даже если предположить, что после устранения хотя бы 2-х из трёх недоразумений оценка поменялась бы на 9, то средний бал для 1 работы был бы (9+9+8+8+8+8+10+8)/8 = 8,5. А при её исключении (9+8+8+8+8+10+8)/7 = 8,43.
Что в любом случае выше, чем предполагаемый балл 8,4 для работы номер 3 после исключения одной из оценок.
Не могу исключать, что у команды Broxus (работа под номером 2) тоже есть вопросы к оценкам.
Что можно здесь сказать?
В силу наличия субъективной составляющей судейство не идеально. В будущем, в таких конкурсах мы даже увидим борьбу стейков и здравого смысла. Поэтому продумывать и закладывать правильные решения, исключающие возможность манипулирования оценкой, в основе G2.0 однозначно нужно, хотя на первый взгляд конкретные меры не очевидны.
На данный момент, я лично для себя сделал некоторые выводы, которые буду использовать в дальнейших конкурсах для того, чтобы мои работы были более дружественны к жюри. И чтобы возникало как можно меньше недопонимания. Это то, что я могу сделать сам – постараться исключить возможности для конфликтов насколько это возможно.
Данным постом я ни в коем случае не хотел бы обвинять/осуждать кого-то в чём-то, и уж тем более переходить на личности. Несмотря на своё несогласие с оценкой, я уважаю мнение жюри, и считаю, что споры с ним - крайне непродуктивный путь. Подумайте о том, к чему приведёт апелляция каждым участником конкурса на каждую не понравившеюся ему оценку? Сколько их будет и как долго все они будут изучаться? Кто именно и на каких основаниях будет рассматривать такие апелляции? Уровень компетенции арбитража должен быть даже бОльшим, чем основного состава жюри, и достичь этого прямо сейчас невозможно. Потому что даже в основном составе жюри слишком мало тех, кто считает себя достаточно компетентным для оценки некоторых работ. Например, в конкурсе атомарных свопов работы 1 и 2 получили всего по 8 оценок, а работа 3 – только 6.
Поэтому я склоняюсь только к тем мерам, которые просты и однозначно могут привести к повышению уровня доверия всего сообщества к оценке работы. Например:
- Увеличение количества членов жюри без опускания планки его профессионализма. Нужно проводить повторные конкурсы для набора жюри либо даже периодически переизбирать текущий состав, а также повысить вознаграждение для голосовавших. Новые люди приходят в сообщество постоянно, какие-то - покидают. А состав жюри (1.1) пока не менялся.
При малом количестве голосов доверительный интервал для оценки будет большой, что может вызвать желание конкурсантов пересчитать результаты. Ведь получается, что всего одна оценка сильно влияет на конечный результат, как это показано в моём и других примерах.
При большом количестве голосов итоговая оценка будет близка к объективной даже в случае совершения каким-либо членом жюри ошибки.
- Формирование различных специализированных групп жюри. Один человек не может хорошо разбираться в смарт-контрактах и UI дизайне, чтобы одинаково хорошо оценивать и то и другое. К счастью, формирование таких групп уже происходит в настоящий момент.
- Возможность (либо даже обязанность) для жюри давать более развёрнутую оценку. Сейчас фидбек довольно короткий, вероятно из-за каких-то ограничений в governance?
Уверен, многие положительные моменты будут реализованы в G2.0, и именно там уже сейчас надо предлагать и обсуждать возможные технические решения.
EN
Hello!
I want to express my agreement with some of the ideas described in this thread. The community is growing fast and the situations described by the contestants will be repeated over and over again.
Our team is no exception. We also participated in the Atomic Swaps Contest (Contest: Atomic Swaps on Free TON [31 August 2020 - 20 September 2020]). The only and lowest score of 7 pts received from the jury for our work at number 1 looked like this:
It can be assumed that the jury member removed 1 point for the shortcomings indicated by him. But the bottom line is that there are links to transactions (the second removed point) and are indicated under each video demonstration, which was mentioned in the submission.
Fee charge is also implemented, which I wrote about in detail in the contest thread in this post. Did the jury member read this thread, where are the other participants gave an answer to this question - I do not know.
You can also argue whether the use of well-working parts of open source projects in other open source solutions after reviewing the code and the necessary edits is not correct, or, on the contrary, preferable (in our practice, customers preferred an open source solution, that it is production-ready).
But even if we assume that after eliminating at least 2 of the three misunderstandings, the score would change to 9, then the average score for 1 job would be (9 + 9 + 8 + 8 + 8 + 8 + 10 + 8) / 8 = 8.5. And if it is excluded (9 + 8 + 8 + 8 + 8 + 10 + 8) / 7 = 8.43.
Which is higher anyway than the estimated 8.4 for job number 3 after dropping one of the grades.
Maybe, the Broxus team also has questions about the estimates?
What can be said here?
Due to the presence of a subjective component, the judging is not ideal. In the future, in such contests, we will even see the struggle between money steaks and common sense. Therefore, it is unambiguously necessary to think over and put in the correct decisions that exclude the possibility of manipulating the assessment, at the heart of G2.0, although at first glance, specific measures are not obvious.
At the moment, I personally made some conclusions for myself, which I will use in future contests in order to make my works more jury-friendly. And so that there is as little misunderstanding as possible. This is something I can do myself - try to eliminate the possibility of conflict as much as possible.
With this post, I in no way would like to accuse someone of something, and even more so to get personal. Despite my disagreement with the assessment, I respect the opinion of the jury, and I think that arguing with him is an extremely unproductive way. Think about what it will lead to an appeal by each participant of the contest for each rating he does not like? How many of them will there be and how long will they all be studied? Who exactly and on what grounds will consider such appeals? The level of competence of the arbitration should be even greater than that of the main jury, and this cannot be achieved right now. Because even in the main jury there are too few of those who consider themselves competent enough to evaluate some works. For example, in the atomic swap contest, works 1 and 2 received only 8 ratings each, and work 3 - only 6.
Therefore, I lean only towards measures that are simple and can unequivocally lead to an increase in the level of confidence of the whole community in the evaluation of the work. For instance:
- Increasing the number of jury members without lowering the bar of their professionalism. It is necessary to hold repeated contests to recruit the jury or even periodically re-elect the current composition. New people come to the community all the time, some leave. And the composition of the jury (1.1) has not changed yet.
With a small number of votes, the confidence interval for the assessment will be large, which may cause the contestants to wish to recount the results. After all, it turns out that just one assessment strongly affects the final result, as shown in my and other examples.
With a large number of votes, the final score will be close to objective, even if any jury member makes a mistake.
- Formation of various specialized jury groups. One person cannot be well versed in smart contracts and UI design in order to evaluate both equally well. Fortunately, the formation of such groups is already underway.
- Opportunity (or even obligation) for the jury to give a more detailed assessment. Now the feedback is rather short, probably due to some kind of governance restrictions?
I am sure that many positive aspects will be implemented in G2.0, and it is there that we need to propose and discuss possible technical solutions right now.